Context
Het gebeurt regelmatig dat er op een dynamische manier csv bestanden uitgelezen moeten worden, bijvoorbeeld wekelijkse rapporten van een bepaalde afdelingen. Daarbij is de bestandsnaam van het csv bestand iedere week anders (dynamisch). Daarnaast moet er voorkomen worden dat een bestand meer dan een keer wordt uitgelezen. Zodra het bestand is uitgelezen dan krijgt het de status “verwerkt”. Als hij deze status heeft zullen er geen verdere mutaties meer mogelijk zijn.
In deze BLOG zal ik uitleggen hoe je een folder met CSV of TEXT bestanden kunt scannen op nieuwe files. Zodra een bestand nieuw is zal hij worden ingelezen en vervolgens zal hij de status “verwerkt” krijgen.
Benodigd
We hebben totaal drie tabellen nodig.
Tabel 1: in deze tabel slaan we de namen op van de CSV bestanden die al zijn uitgelezen;
Tabel 2: in deze tabel slaan we tijdelijk de bestandsnamen op van CSV bestanden uit de folder die wordt gescand;
Tabel 3: in deze tabel slaan we de inhoud van de CSV file(s) op.
Tabel 1: deze tabel heeft twee kolommen nodig. Kolom een bevat de bestandsnaam van het CSV bestand, bijv. varchar(50), kolom twee geeft aan of het bestand verwerkt is dus kan worden volstaan met een bit veld (1 of 0).
Tabel 2: deze tabel heeft een kolom, de bestandsnaam (bijv varchar(50).
Tabel 3: de inhoud van deze tabel is afhankelijk van de CSV file die ingelezen moet worden.
Voorbereiding
Maak een variabele aan op package-scope. Noem deze variable bijvoorbeeld “csvfile” van het formaat String. Zet de waarde op 0. Deze variabele is benodigd om straks de filenames in op te slaan en weg te schrijven naar een tabel.
Takenlijst

Stap 1
De eerste stap die gedaan wordt is het opgeschonen van de staging tabellen, tabel 2 en 3. Er zal dus een Execute SQL Task worden gemaakt die een truncate doet op de twee tabellen, dit spreekt voor zich.
Stap 2
Dit is een ForEachLoop Container die de opgegeven folder gaat scannen op bestanden met de extensie “.csv”. Zodra er een .cvs bestand is gevonden wordt deze weggeschreven in Tabel 2. In de properties van de foreach loop zullen enkele instellingen gedaan moeten worden.
Tabje collection: kies hier de For Each File Enumerator. Kies vervolgens de folder waar de bestanden zijn opgeslagen en kies voor de extensie *.csv. Dit zorgt ervoor dat alle bestanden die deze extensie hebben worden meegenomen. Uiteraard ben je hier vrij om in te vullen wat je wilt, bijvoorbeeld: budget_week*jaar*.*

Tabje Variable Mappings: hier moet de variabele worden gekozen waarin de bestandsnaam moet worden weggeschreven. Aangezien er maar een variabele is aangemaakt kiezen we deze, “user::csvfile” met index 0.

Stap 3
Deze taak bevindt zich in de For Each Loop en schrijft de gevonden bestandsnaam weg in Tabel 2.
Tabje General: stel de connectie in en vul bij SQLStatement in:
INSERT INTO Tabel2(CSVFileName) Values (?)

Tabje Parameter Mapping: hier wordt de variabele gekoppeld aan de input. Met andere woorden; hier geven we aan welke variabele we gebruiken in ons SQL statement en welke het vraagteken vult. We koppelen hier de variabele user::csvfile als input aan onze statement en geven hem het type Varchar mee en Parameter 0. Deze laatste is heel belangrijk. Vergeet je hier de 0 in te vullen zal het niet werken!

Stap 4
Tijdens stap 1 t/m 3 is de folder gescand op CSV bestanden en zijn alle gevonden bestanden weggeschreven in Tabel 2, de staging tabel. Nu willen we weten welke bestanden er nieuw zijn bijgekomen sinds het package voor de laatste keer is gedraaid (de eerste keer zullen alle bestanden nieuw zijn). We gaan dit controleren door Tabel 2 te vergelijken met Tabel 1. We zullen kijken welke bestandsnamen nieuw zijn en schrijven deze vervolgens weg in Tabel 1. Hiervoor maken we een Dataflow Task aan.

Als eerste wordt er een OLEDB source aangemaakt die alle records van Tabel 2 ophaalt. Daarna vindt er een lookup plaats. Deze lookup kijkt naar Tabel 2 en vergelijkt de bestandsnamen met Tabel 3. De nieuwe records die worden gevonden zullen worden weggeschreven in een OLEDB destination, Tabel 3. De overige records wordt niks mee gedaan en belanden in de Trash Destination (dit is een gratis addon).

Stap 5
In stap 4 hebben we de bestandsnamen die nog niet voorkwamen weggeschreven in tabel 3. Tabel 3 bevat een extra kolom, IsVerwerkt. Deze geeft aan of het bestand al is uitgelezen of niet. Omdat de nieuwe bestanden uiteraard nog niet zijn uitlezen krijgen deze de status 0. Dit doen we met een Execute SQL task:
UPDATE Tabel3 SET IsVerwerkt = 0 WHERE IsVerwerkt IS NULL
Stap 6
Als het goed is hebben we nu een correcte tabel 3 waarin staat welke bestanden inmiddels zijn verwerkt (status TRUE) en welke nog moeten worden verwerkt (status FALSE). Om die laatste gaat het uiteraard. In stap 6 zullen we de bestanden die een status FALSE hebben gaan uitlezen en plaatsen in Tabel 1. Deze taak zal opnieuw de folder scannen en bekijken welke bestanden een status van IsVerwerkt FALSE hebben in tabel 3.
Herhaal stap 2 met dezelfde instellingen.
Stap 7
Stap 7 bekijkt of de gevonden bestandsnaam een status 0 heeft. De volgende statement wordt gebruikt:
SELECT CSVFileName FROM Tabel1 WHERE [IsVerwerkt] = 0
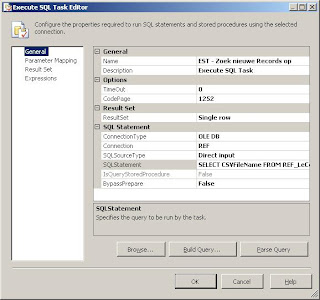
Zet resultset op Single row en voer in het tabblad Result Set in: ResultName: CSVFileName (deze moet overeenkomen met je SQL-statement), Variable name: user::csvfile

Stap 8
Op deze stap ga ik niet te diep in. Wat hier gedaan moet worden is het bestand dat nog niet is verwerkt uitlezen. De bestandsnaam moet dynamisch zijn. Zodra we de dataflow ingaan moet de bestandsnaam dus worden aangepast aan de naam van het bestand. Maak hiervoor een flat file connection manager aan en maak mbv een expressie de connectionstring variabel, in mijn geval:
@[User::filepath]+ @[User::csvfile]. De eerste is een variable die ik zelf gebruik om het filepath te vullen, hier kun je ook bijv C:\ invoeren. Door dit te doen zal de connectionstring iedere keer worden aangepast met de naam van het bestand waarmee je de loop ingaat.
Stap 9
Het bestand is nu uitgelezen dus is hij automatisch verwerkt. Wat er nog gedaan moet worden is de status van IsVerwerkt op 1 zetten. Dit doen we met een Execute SQL Task met het volgende statement:
UPDATE Tabel3 SET IsVerwerkt = 1 WHERE CSVFileName = ?
Het vraagtekentje vullen we door een parameter mapping aan te maken, csvfile, input, varchar, 0.

Dat was het voor zover. Ik weet niet of dit de beste methode is om een folder met CSV’s uit te lezen en vervolgens in te lezen maar in mijn situatie werkt het prima. Mochten er vragen of opmerkingen zijn, schroom niet om een reply te posten!
-Ronald

















































{kind=link}